
3.5 ex1:linear regression
ex1:linear regression
概述
在这部分练习中,您将使用一个变量进行线性回归,以预测一辆餐车的利润。假设您是一家餐饮连锁店的首席执行官,正在考虑在不同城市开设新的分店。该连锁店已在多个城市拥有餐车,您也掌握了这些城市的利润和人口数据。
必要的文件如下:
ex1.py-引导您完成练习的Python文件ex1data1.txt-单变量线性回归的数据集computeCost.py-计算线性回归成本的函数gradientDescent.py-运行梯度下降的函数
导入
1 | import matplotlib.pyplot as plt |
在Python中,from computeCost import *是一种导入语句,用于从computeCost模块导入所有的公共对象(例如函数、类、变量等)。这意味着你可以直接使用这些对象,而无需通过模块名来引用它们。
例如,假设computeCost模块中有一个函数compute_cost(),那么你可以直接调用compute_cost(),而不需要写成computeCost.compute_cost()
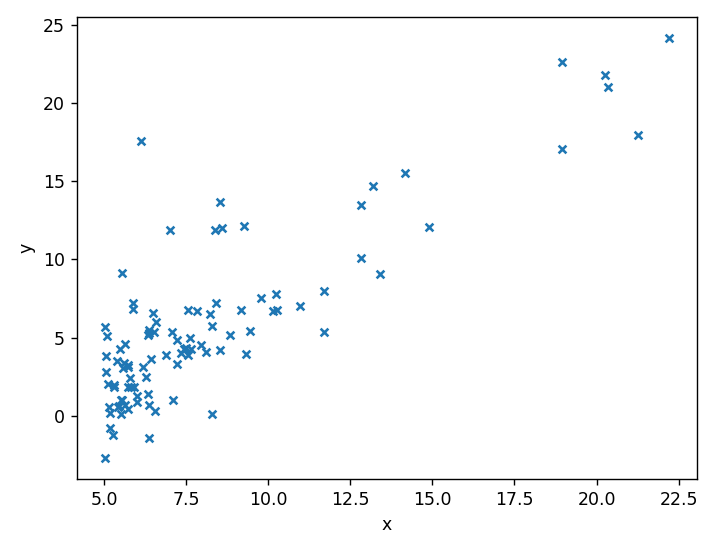
读取并绘图
1 | data=pd.read_csv('ex1data1.txt',header=None,names=['x','y']) |
pd.read_csv函数表示:读取ex1data1.txt这个文件,header=None表示第一行是数据,而不是列名,names=['x','y']意味着DataFrame将有两列,第一列的列名是x,第二列的列名是y。
plt.plot函数表示,横轴的数据是data中名字叫x的列,纵轴的数据是data中名字叫y的列,散点的标记是x图案
梯度下降
插入$x_0$参数列
1 | data.insert(0,'one',1) |
在data的第1列,插入元素为1的列,并且把这列的名字命名为one
在多变量线性回归这一节的开头,解释了原因:
多元线性回归时的映射$h$被表述为:
这个公式中有$n+1$个参数和$n$个变量,为了表述的方便,我们会在样本中新增一个特征量记为$x_0^{(i)}=1,(i=1,2,\cdots,n)$,则公式转化为:
在此情况下只需要定义这样的两个向量:
就可以将前面的映射表述为向量内积的形式:
插入$x_0=1$的列,可以将$h_{\boldsymbol{\theta}}$变为向量内积的形式,便于$\theta$的计算
1 | print(data.head()) |
展示data的前5行,看一下是否是我们所设置的那样,可以看到有3列,名字分别是one,x,y
代价函数
1 | col=data.shape[1] |
data.shape[1]表示的是data列的数量,赋值给col,实际上是3
接下来使用了Pandas的iloc函数的切片语法
X:表示data的前两列,即$x_0$和$x_1$的数据y:表示data的最后一列,即最后的y的数据theta:使用numpy中的zeros函数,初始化成了[0,0]形式,数量和x的个数肯定是相等的
接下来,编写computeCost.py文件中的compute_cost(X, y, theta)函数,计算代价
代价函数的计算公式是:
1 | import numpy as np |
X是一个$(n,2)$的数组,y是一个$(n,1)$的数组,thetas是一个$(2,)$的数组,X @ theta就表示了$h_{\boldsymbol{\theta}}(\boldsymbol{x})=\boldsymbol{\theta}^T\boldsymbol{x}$,其中@的意思是要用矩阵乘法,而不是元素乘法,X @ theta会让X中的每一行都和theta中元素做点积,即计算结果是一个$(n,1)$的数组
np.power是幂的计算函数,参数为2,意味求$h_{\boldsymbol{\theta}}(\boldsymbol{x})-y$的二次幂,因为是数组的运算,所以把数组中每个元素都变为其二次幂的形式
np.sum将数组中每个元素全部都相加在一起,最后除以2倍X数组的元素个数,即为$\frac{1}{2m}$
再回到ex1.py文件中来,将之前写的X,y,theta代入到compute_cost函数中去
1 | print(compute_cost(X, y, theta)) |
完全符合预期
梯度下降
在编写梯度下降函数之前,先设置参数,这里吧迭代次数iterations设置成1500次,学习率alpha设置为0.01
1 | iterations = 1500 |
再编写gradient_descent.py中的gradient_descent(X, y, theta, alpha, iters)函数,完成梯度下降功能
1 | def gradient_descent(X, y, theta, alpha, iters): |
设置一个大小为iters的数组cos,用来记录每次迭代theta所产生的代价
在一个执行iters(1500)次的循环中,
y_pred表示模型的预测值即$h_{\boldsymbol{\theta}}(\boldsymbol{x})=\boldsymbol{\theta}^T\boldsymbol{x}$error表示模型和真实值的误差: $\boldsymbol{\theta}^T\boldsymbol{x}- y$cost[i] = compute_cost(X, y, theta):将每次theta的参数代入代价函数中计算代价theta -= (alpha / m) * (X.T @ error):这里直接就是矩阵之间的减法,对应元素会直接相减,体现了矢量化的思想
梯度下降的公式
其中
即
最后返回一个theta数组和一个cost数组,theta里面的$\theta$值就是梯度下降1500次过后的$\theta$
回到ex1.py中,接下来调用gradient_descent函数
1 | theta,cost= gradient_descent(X, y, theta, alpha, iterations) |
输出theta,结果符合预期
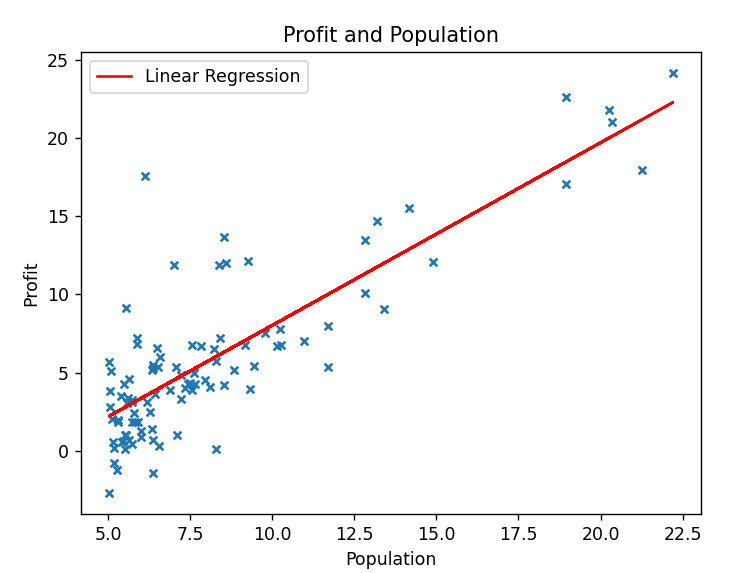
再根据梯度下降后的theta数组,绘制拟合曲线
1 | pred=X@theta.T #根据x值预测出的y值 |
把预测值$h_{\boldsymbol{\theta}}(\boldsymbol{x})=\boldsymbol{\theta}^T\boldsymbol{x}$插入到data的第4列中去,这样做是因为,Pandas的plot函数必须要使用Pandas对象中的列作为参数
plot函数将名称为x的列作为横轴,把pred作为纵轴,曲线命名为Linear Regression,颜色为红色,绘制图像
设置x,y轴的名称,图像标题,展示图例,展示图像后:
再展示cost数组的内容,将梯度下降的内容展示出来
1 | plt.plot(np.arange(1500),cost) |
把0~1500的连续值设置为x轴,把cost的值设置为y轴,绘制并展示图像
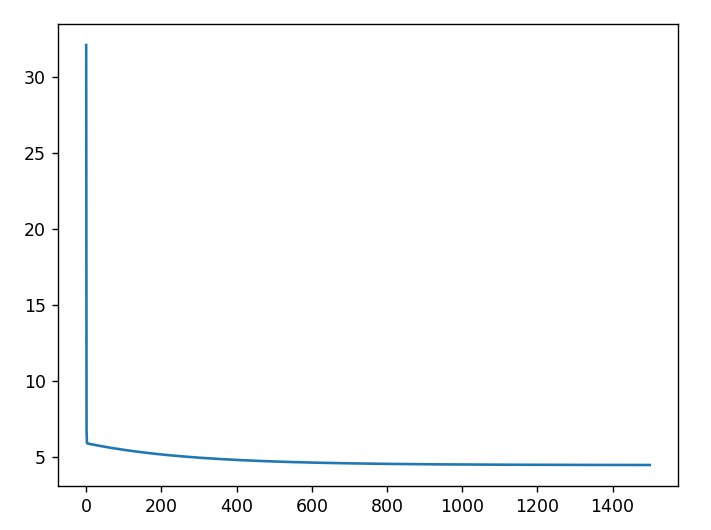
可以看到,经过1500次的迭代,代价cost在逐渐接近0,说明拟合效果很好
最后我们解决一下实际问题,预测一下Population为35000的城市,利润有多少?
1 | predict=np.array[1,3.5]@theta |

